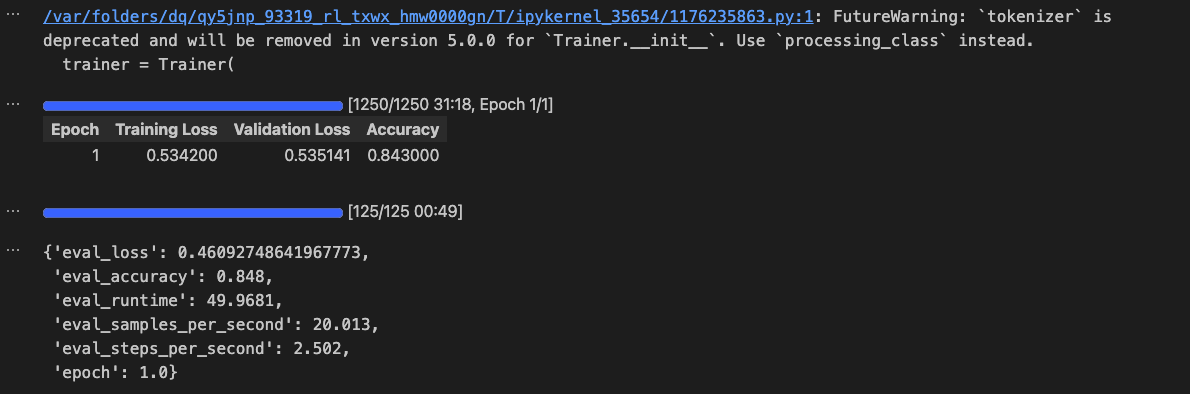
LLM을 클라우드 환경이나 Google Colab에서 파인튜닝하는 과정에서 종종 라이브러리 간 의존성 충돌로 인해 실행 오류가 발생하고, 높은 메모리 사용량과 긴 학습 시간이 문제가 되곤 합니다. 이러한 문제를 해결할 수 있는 보다 효율적인 방법을 찾던 중, 단일 GPU 환경에서도 최적의 성능을 제공하는 "Unsloth"를 접하게 되어 소개해 보겠습니다.1. Unsloth란 무엇인가?Unsloth는 LLM(대형 언어 모델) 파인튜닝을 보다 효율적으로 수행할 수 있도록 설계된 혁신적인 도구입니다. Michael과 Daniel Han 형제가 개발한 이 프로젝트는 적은 자원으로도 강력한 성능을 발휘할 수 있도록 최적화되어 있으며, 학습 속도 향상과 메모리 사용량 절감을 주요 목표로 하고 있습니다.Unsloth..