본 내용은 하단 참고자료에 작성된 책에 대한 내용을 기반으로 다시한번 정리한 내용입니다.
예제를 통해 연합뉴스 기사의 제목을 바탕으로 카테고리를 예측하는 딥러닝 모델을 개발하는 과정을 정리하였습니다. 이를 위해 데이터셋 로드부터 모델 학습 및 평가까지의 전체 과정을 단계별로 설명하며, 주요 개념과 코드 실행 결과를 함께 살펴보도록 하겠습니다.
1. 모델 학습에 사용할 연합뉴스 데이터셋 다운로드
모델 학습을 위해 KLUE 데이터셋의 YNAT 서브셋을 사용합니다. datasets 라이브러리의 load_dataset 함수를 이용하여 데이터를 로드합니다.
from datasets import load_dataset
klue_tc_train = load_dataset('klue', 'ynat', split='train')
klue_tc_eval = load_dataset('klue', 'ynat', split='validation')
데이터를 출력해 보면 다음과 같은 구조를 확인할 수 있습니다.
# klue_tc_train
Dataset({
features: ['guid', 'title', 'label', 'url', 'date'],
num_rows: 45678
})
# klue_tc_train[0]
{'guid': 'ynat-v1_train_00000',
'title': '유튜브 내달 2일까지 크리에이터 지원 공간 운영',
'label': 3,
'url': 'https://news.naver.com/main/read.nhn?mode=LS2D&mid=shm&sid1=105&sid2=227&oid=001&aid=0008508947',
'date': '2016.06.30. 오전 10:36'}
각 샘플은 기사 제목(title), 카테고리(label), 기사 링크(url), 날짜(date) 등의 정보를 포함하고 있습니다. label 값은 숫자로 되어 있어 어떤 카테고리에 해당하는지 직관적으로 이해하기 어려우므로, 카테고리명을 확인해 보겠습니다.
# klue_tc_train.features['label'].names
['IT과학', '경제', '사회', '생활문화', '세계', '스포츠', '정치']
2. 불필요한 컬럼 제거
모델 학습에 불필요한 컬럼(guid, url, date)을 제거하고, 필요한 컬럼(title, label)만 남기도록 하겠습니다.
klue_tc_train = klue_tc_train.remove_columns(['guid', 'url', 'date'])
klue_tc_eval = klue_tc_eval.remove_columns(['guid', 'url', 'date'])
# klue_tc_train
Dataset({
features: ['title', 'label'],
num_rows: 45678
})
3. 카테고리를 문자로 표기한 label_str 컬럼 추가
필요한 컬럼들을 남겨놓았으나, label이 아직 숫자라 가독성이 떨어진다는 단점이 있습니다. 카테고리를 확인하기 쉽도록 새롭게 label_str 컬럼을 추가해주겠습니다.
# klue_tc_train.features['label']
ClassLabel(names=['IT과학', '경제', '사회', '생활문화', '세계', '스포츠', '정치'], id=None)
klue_tc_label = klue_tc_train.features['label']
def make_str_label(batch):
batch['label_str'] = klue_tc_label.int2str(batch['label'])
return batch
klue_tc_train = klue_tc_train.map(make_str_label, batched=True, batch_size=1000)
# klue_tc_train[0]
{'title': '유튜브 내달 2일까지 크리에이터 지원 공간 운영', 'label': 3, 'label_str': '생활문화'}
klue_tc_train.features['label'] 을 출력해보면 ClassLabel 객체로 이루어진걸 볼 수 있습니다. 해당 객체는 숫자를 입력하면 해당 숫자에 맵핑된 카테고리를 반환해주는 int2str() 함수를 지니고 있습니다. 그리고 데이터셋의 요소별로 함수를 실행시켜주는 map 함수를 이용해서 batch_size씩 make_str_label을 실행해서 데이터 요소별로 label_str 컬럼을 만들어주었습니다.
4. 학습/검증/테스트 데이터셋 분할
빠른 실습 진행을 위해 학습 데이터셋을 부분적으로 추출하고 학습이 잘 되고 있는지 확인할 검증 데이터와 성능 확인에 사용할 테스트 데이터는 검증 데이터셋에서 각각 추출하여 사용하였습니다.
train_dataset = klue_tc_train.train_test_split(test_size=10000, shuffle=True, seed=42)['test']
dataset = klue_tc_eval.train_test_split(test_size=1000, shuffle=True, seed=42)
test_dataset = dataset['test']
valid_dataset = dataset['train'].train_test_split(test_size=1000, shuffle=True, seed=42)['test']
train_test_split 메서드를 사용하면 입력한 test_size or train_size 값을 기준으로 학습 데이터셋과 테스트 데이터셋을 분리해줍니다.
shuffle는 데이터를 섞어서 분할한다는 의미를 지니고 있습니다.
train_dataset = klue_tc_train.train_test_split(test_size=10000, shuffle=True, seed=42)
# train_dataset
DatasetDict({
train: Dataset({
features: ['guid', 'title', 'label', 'url', 'date'],
num_rows: 35678
})
test: Dataset({
features: ['guid', 'title', 'label', 'url', 'date'],
num_rows: 10000
})
})
위에서 확인했던 전체 데이터수 45678개에서 명시한 test_size만큼 test 데이터셋이 생기고 나머지는 train 데이터셋으로 생성된 모습을 볼 수 있습니다. 테스트 데이터와 검증 데이터는 서로 다른 데이터를 사용해야하기 때문에 klue_tc_eval 데이터셋에서 1차적으로 train_test_split 메서드를 사용한 dataset의 test 데이터셋을 테스트 데이터로 이용했고, 남은 train 데이터셋에서 한번 더 train_test_split 메서드를 활용해 검증 데이터를 생성한 모습을 볼 수 있습니다.
5. Trainer를 사용한 학습
이제 모든 데이터셋을 준비하였으니 모델을 학습 시키도록 하겠습니다.
import torch
import numpy as np
from transformers import (
Trainer,
TrainingArguments,
AutoModelForSequenceClassification,
AutoTokenizer
)
def tokenize_function(examples):
return tokenizer(examples["title"], padding="max_length", truncation=True)
model_id = "klue/roberta-base"
model = AutoModelForSequenceClassification.from_pretrained(model_id, num_labels=len(train_dataset.features['label'].names))
tokenizer = AutoTokenizer.from_pretrained(model_id)
train_dataset = train_dataset.map(tokenize_function, batched=True)
valid_dataset = valid_dataset.map(tokenize_function, batched=True)
test_dataset = test_dataset.map(tokenize_function, batched=True)
klue/roberta-base는 바디만 있는 모델인데, 이를 AutoModelForSequenceClassification로 불러오면 분류 헤드 부분이 랜덤으로 초기화됩니다. 따라서 분류 헤드의 분류 클래스 수를 지정하기 위해 num_labels에 데이터셋의 레이블 수를 지정해줬습니다.
training_args = TrainingArguments(
output_dir="./results",
num_train_epochs=1,
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
evaluation_strategy="epoch",
learning_rate=5e-5,
push_to_hub=False
)
def compute_metrics(eval_pred):
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
return {"accuracy": (predictions == labels).mean()}
여기 코드 부분이 이해가 잘 되지 않았기에 자세하게 설명하고 넘어가도록 하겠습니다. 코드별 상세 설명은 다음과 같습니다.
output_dir : 결과를 저장할 디렉토리 위치
num_train_epochs : 학습할 에포크 수
per_device_train_batch_size : 학습 시 디바이스당 배치 크기
per_device_eval_batch_size : 평가 시 디바이스당 배치 크기
,evaluation_strategy="epoch" : 평가 전략, 여기서는 매 에포크마다 평가
learning_rate=5e-5 : 학습률
push_to_hub=False : 모델을 Hugging Face Hub에 푸시할지 여부
eval_pred : 평가 예측값과 실제 레이블을 포함하는 튜플 (logits, labels)
logits : 모델의 예측값
labels : 실제 레이블
predictions : logits에서 가장 높은 값을 가진 인덱스를 예측값으로 반환
accuracy : 예측값과 실제 레이블이 일치하는 비율을 계산하여 반환
compute_metric 메서드가 이해가 잘 되지 않았는데, 해당 평가 메트릭이 한번만 실행된다고 하는데, 어떤식으로 평가가 이루어지는가 이해가 잘 되지 않았고, logits와 labels에 값이 어떤 형태로 어떤 값이 들어가는지 잘 모르겠었습니다. 하지만 다음 샘플 코드를 통해 완벽하게 이해했습니다.
import numpy as np
# 샘플 데이터 (검증 데이터셋 크기: 1000개, 클래스 수: 6개)
logits = np.random.rand(1000, 6) # 1000개의 샘플, 6개의 클래스에 대한 예측값
labels = np.random.randint(0, 6, size=1000) # 1000개의 실제 레이블 (0, 1, 2, 3, 4, 5 중 하나)
# logits
logits = np.array([
[0.1, 0.2, 0.3, 0.4, 0.5, 0.6], # 첫 번째 샘플의 예측값
[0.6, 0.5, 0.4, 0.3, 0.2, 0.1], # 두 번째 샘플의 예측값
[0.1, 0.3, 0.5, 0.7, 0.9, 0.2], # 세 번째 샘플의 예측값
# ... (997개의 샘플 더)
])
# labels
labels = np.array([5, 0, 4, ...]) # 1000개의 실제 레이블
앞에서 지정했던 레이블 수를 기준으로 각 데이터 요소별로 어떤 레이블에 해당하는지 예측값을 지정하고 배열형태로 담습니다. 그 후 labels에 저장된 정답 레이블과 비교를 하여 mean 메소드를 통해 일치하면 True, 그렇지 않으면 False로 이루어진 불리언 배열에서 True의 비율을 계산하여 최종 정확도를 반환하는 구조였습니다. 결국 정확도는 예측값인 logits와 실제 레이블값인 labels의 일치 비율을 나타낸 것이었습니다. 최종적인 모델 학습 및 평가 코드는 다음과 같았습니다.
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=valid_dataset,
tokenizer=tokenizer,
compute_metrics=compute_metrics,
)
trainer.train()
trainer.evaluate(test_dataset)
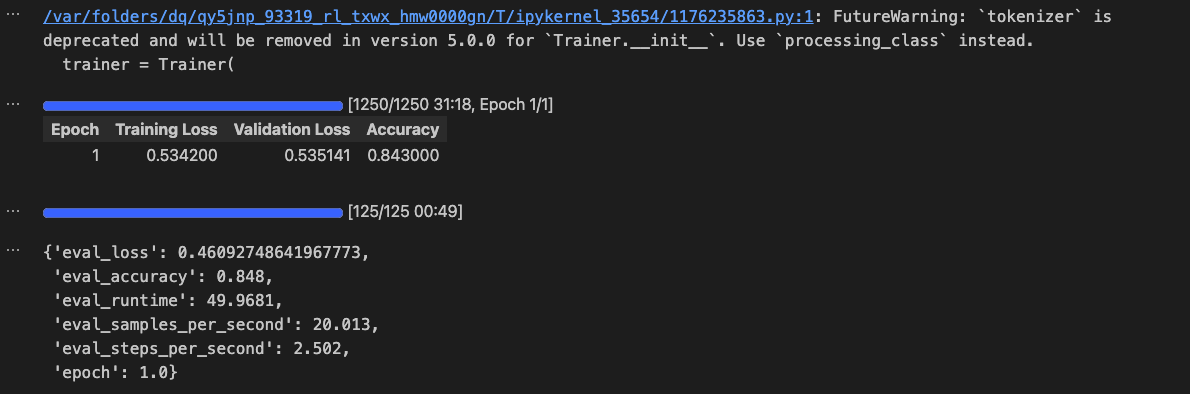
아래와 같은 84%의 정확도를 얻을 수 있었습니다.
참고자료
LLM을 활용한 실전 AI 애플리케이션 개발 - 허정준
'DeepLearning' 카테고리의 다른 글
| [Text Embedding] 텍스트를 임베딩하는 3단계 (0) | 2025.04.11 |
|---|---|
| [Transformer] RNN과 트랜스포머 아키텍처의 이해 (0) | 2025.04.10 |
| [DeepLearning] 메모리 효율적인 딥러닝 (0) | 2025.04.08 |
| [DeepLearning] 언어 모델 최적화 개념 정리 (0) | 2025.02.14 |
| [DeepLearning] 용어 정리 (0) | 2025.02.12 |