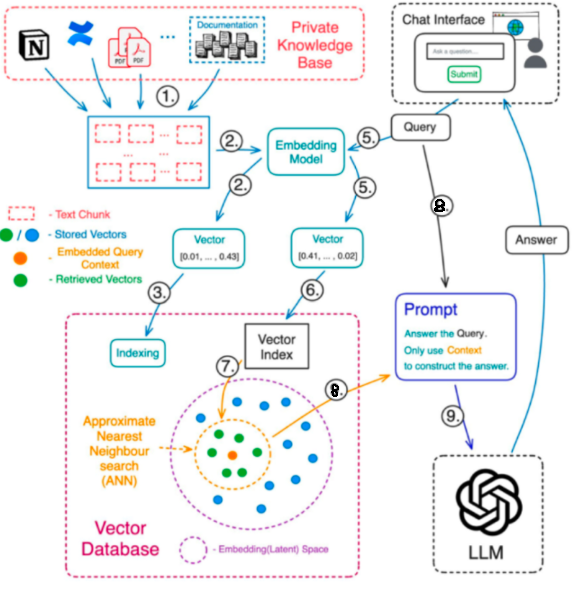
LLM(Large Language Model)과 RAG(Retrieval-Augmented Generation) 시스템의 성능을 평가하는 것은 AI 애플리케이션 개발에서 중요한 과정입니다. 다양한 평가 프레임워크들이 각자 독특한 특징과 접근 방식을 제공합니다. 이 글에서는 주요 평가 프레임워크들을 비교하고 각각의 장단점을 살펴보겠습니다. 1. LLM-as-a-judge1) 개념LLM이 평가자 역할을 수행하여 다른 모델이나 시스템의 성능을 평가인간 평가자 대신 LLM을 활용하여 대규모 평가 가능프롬프트 엔지니어링을 통해 평가 기준과 방법 설정2) 장점인간 평가보다 비용 효율적일관된 평가 기준 적용 가능대규모 평가에 적합3) 한계LLM 자체의 편향이 평가에 영향을 줄 수 있음특정 언어나 도메인에 따라 성능 ..