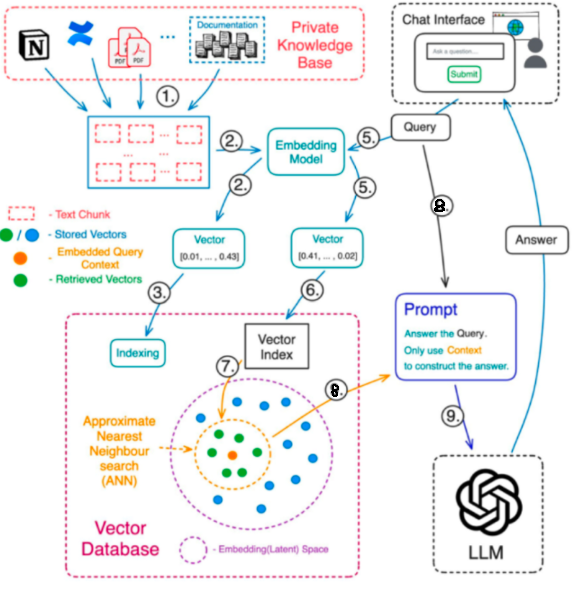
LangGraph를 활용한 RAG 시스템의 챗봇을 과제로 진행하던 도중, 팀장님의 조언으로 동일한 질문에 대해 캐싱을 사용해 비용과 시간을 효율적으로 사용하라는 말씀을 들었습니다. 이에 따라 캐싱을 사용해 보다 더 효율적인 RAG 시스템을 구축하고자 하였습니다. 1. 문제상황아래는 사용자의 같은 질문에 대해 소요된 시간과 토큰에 대한 이미지입니다. 보시다시피 같은 질문임에도 똑같은 노드 순환을 반복하며 시간과 토큰이 소모되는 모습입니다. 2. InMemoryCache (/w Langchain)langchain에서 캐싱을 위한 라이브러리를 제공해주어서 사용해보았습니다.from langchain.globals import set_llm_cachefrom langchain_community.cache im..