Dacon에서 진행하는 "난독화된 한글 리뷰 복원 AI 경진대회"를 뒤늦게 접하게 되어 LLM을 활용한 문제해결능력을 기르고자 경진대회에 참여하기로 하였습니다. 핵심 주제는 "식별하기 어렵게 쓴 한글 리뷰를 원래 한글 리뷰로 복원하는 AI 알고리즘 개발" 이었습니다.
데이터셋과 샘플 코드를 모두 제공해주었기에 이를 먼저 실행해보았습니다.
import pandas as pd
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig, pipeline
train = pd.read_csv('./drive/MyDrive/data_set/open/train.csv', encoding = 'utf-8-sig')
test = pd.read_csv('./drive/MyDrive/data_set/open/test.csv', encoding = 'utf-8-sig')
samples = []
for i in range(10):
sample = f"input : {train['input'][i]} \n output : {train['output'][i]}"
samples.append(sample)
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type= 'nf4',
bnb_4bit_use_double_quant = True,
bnb_4bit_compute_dtype=torch.bfloat16
)
model_id = 'beomi/gemma-ko-7b'
model = AutoModelForCausalLM.from_pretrained(model_id, quantization_config = bnb_config, device_map={"":0})
tokenizer = AutoTokenizer.from_pretrained(model_id)
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = 'right'
pipe = pipeline(
task="text-generation",
model=model,
tokenizer=tokenizer
)
restored_reviews = []
for index, row in test.iterrows():
query = row['input']
messages = [
{
"role": "system",
"content": (
"You are a helpful assistant specializing in restoring obfuscated Korean reviews. "
"Your task is to transform the given obfuscated Korean review into a clear, correct, "
"and natural-sounding Korean review that reflects its original meaning. "
"Below are examples of obfuscated Korean reviews and their restored forms:\n\n"
f"Example, {samples}"
"Spacing and word length in the output must be restored to the same as in the input. "
"Do not provide any description. Print only in Korean."
)
},
{
"role": "user",
"content": f"input : {query}, output : "
},
]
prompt = "\n".join([m["content"] for m in messages]).strip()
outputs = pipe(
prompt,
do_sample=True,
temperature=0.2,
top_p=0.9,
max_new_tokens=len(query),
eos_token_id=pipe.tokenizer.eos_token_id
)
generated_text = outputs[0]['generated_text']
result = generated_text[len(prompt):].strip()
restored_reviews.append(result)
submission = pd.read_csv('./drive/MyDrive/data_set/open/sample_submission.csv', encoding = 'utf-8-sig')
submission['output'] = restored_reviews
submission.to_csv('./baseline_submission.csv', index = False, encoding = 'utf-8-sig')
gemma 7b 모델을 4비트 양자화를 사용하여 추론하는 코드였습니다.

구글 코랩 무료 버전을 사용하니 거의 2시간을 추론과정에서 사용하더니 OOM이 발생하였습니다...cpu 메모리도 사용하게 수정해서 다시 실행해도 똑같이 OOM이 발생하여 이번 기회에 클라우드 환경에서 코드를 실행하고 모델을 파인튜닝 해보도록 하였습니다. 비용이 너무 비싸서 고민하다가 "elice cloud"가 비용이 저렴하고 무료 크레딧을 제공하는걸 보고 사용해보게되었습니다.

가입을하고 클라우드를 사용하려고할때 위와같이 기관 정보를 입력하라고 나오는데 크게 의미는 없고 그냥 도메인 정도라고 생각하시면 될 것 같습니다.

이벤트중인지 결제 수단을 등록하면 무료 크레딧을 제공해줘서 좋았습니다. 그럼 이제 본격적으로 인스턴스를 생성하고 GPU를 활용해 보도록 하겠습니다.

인스턴스가 여러 유형이 있는데 코랩 무료 버전보다는 gpu 메모리의 양이 많으면서도 최소한의 비용을 사용하고자 "G-NAHPM-20" 인스턴스를 선택하였습니다.
환경은 주피터 노트북으로 하였고 크게 설정할 것 없이 유형과 환경을 지정하고 기다리면 금방 인스턴스가 생성되고 이용할 수 있어서 굉장히 편리했습니다.

상단 크레딧이 시간 단위가 아니라 실시간으로 차감 돼서 지출이 직관적으로 보여서 좋았습니다.
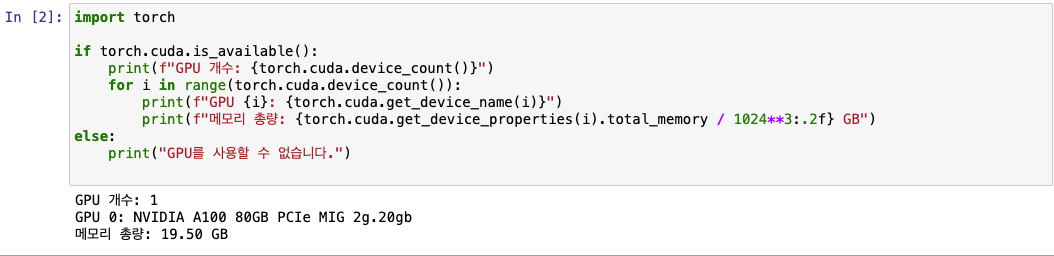
인스턴스가 잘 생성되었는지 Gpu 메모리를 확인해보았고, 잘 만들어진 모습을 볼 수 있었습니다. 이제 기존 코랩에서 OOM이 발생했던 샘플코드를 다시 실행해 보았습니다.
'DeepLearning' 카테고리의 다른 글
| [DeepLearning] 언어 모델 최적화 개념 정리 (0) | 2025.02.14 |
|---|---|
| [DeepLearning] 용어 정리 (0) | 2025.02.12 |
| [DeepLearning] 제목 기반 카테고리 예측 모델 개발 (0) | 2025.02.09 |