프로젝트에서 지도를 통해 학교 주변의 가게 정보와 자취방 정보를 함께 제공하려고 합니다. 그러나 이러한 정보는 공공 데이터에서 제공되지 않으며, 별도의 API도 존재하지 않습니다. 따라서 이번 기회를 활용해 직접 크롤링을 통해 데이터를 수집하려고 합니다. 오늘은 우선 가게들의 이름만 크롤링을 통해 가져오는 것을 목표로 하겠습니다.
1. Crawling 이란
2. Python Crawling 라이브러리
3. Code Review
1. Crawling 이란
웹 크롤링은 웹 사이트에 있는 정보를 자동으로 빠르게 수집하는 기술입니다. 이는 데이터 분석, 웹사이트 자동화, 인공지능 학습 데이터 수집 등 다양한 분야에서 활용되고 있습니다. 저는 이번 프로젝트에서 파이썬을 사용해 크롤링을 진행할 예정입니다. 파이썬 크롤링은 크게 두 가지 방식으로 나뉩니다. 첫 번째는 정적인 페이지를 다룰 때 사용하는 "BeautifulSoup"이며, 두 번째는 동적인 페이지를 다룰 때 사용하는 "Selenium"입니다. 이번 작업에서는 네이버 지도에서 다양한 화면과 상호작용하며 여러 데이터를 수집해야 하므로, "Selenium"이 더 적합하다고 판단해 이를 사용하여 크롤링을 진행했습니다.
2. Python Crawling 라이브러리
본격적인 크롤링 과정에 앞서 Python에서 사용되는 Crawling 라이브러리들을 간단하게 소개하고 넘어가겠습니다.
1) BeautifulSoup
주로 정적 웹 페이지(데이터의 추가적인 변경이 일어나지 않는 페이지) 에서 간단하고 빠르게 데이터를 추출할 때 사용합니다. 일반적으로 HTML이나 XML 문서에서 특정 요소를 찾고 데이터를 수집하는 데 적합합니다.
2) Selenium
주로 동적 웹 페이지(데이터의 추가적인 변경이 일어나는 페이지)를 처리하거나, 사용자 상호작용을 자동화해야 할 때 사용합니다. 브라우저를 실제로 제어할 수 있어 다양한 상황에 대응할 수 있습니다. 또한 JavaScript 가 많이 사용된 사이트의 크롤링에 적합합니다.
3) Scrapy
대규모 웹 크롤링과 구조화된 데이터 추출에 매우 적합한 도구입니다. 또한, 작은 규모의 크롤링 작업이나 간단한 데이터 추출에는 다소 과할 수 있지만, 복잡하고 대규모 작업에서는 매우 효율적입니다. 그러나 기본적으로 정적 웹페이지 크롤링에 최적화되어 있으며, 동적 페이지 처리나 사용자 상호작용이 필요한 경우에는 한계가 있어 Selenium이나 Splah와 같은 도구를 함께 사용해야 할 수 있습니다.
3. Code Reivew
1) Selenium 사용을 위한 준비
from selenium import webdriver as wb
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from time import sleep
driver = wb.Chrome()
driver.get('https://map.naver.com/')
Selenium을 사용하기 위패 필요한 모듈들을 임포트하고 Chrome 웹 드라이버를 초기화합니다.
2) 키워드 검색
search = driver.find_element(By.CSS_SELECTOR, ".input_search")
search.send_keys("호서대 음식점")
search.send_keys(Keys.ENTER)
driver.get()을 통해 웹 페이지 로드를 완료했다면 크롬창으로 네이버 지도 화면이 열릴 것 입니다. 이제 여기서 검색창에 해당하는 class를 찾고 "호서대 음식점"을 입력하는 이벤트 처리를 해줍니다. 그러면 음식점 리스트들이 나올 것입니다.
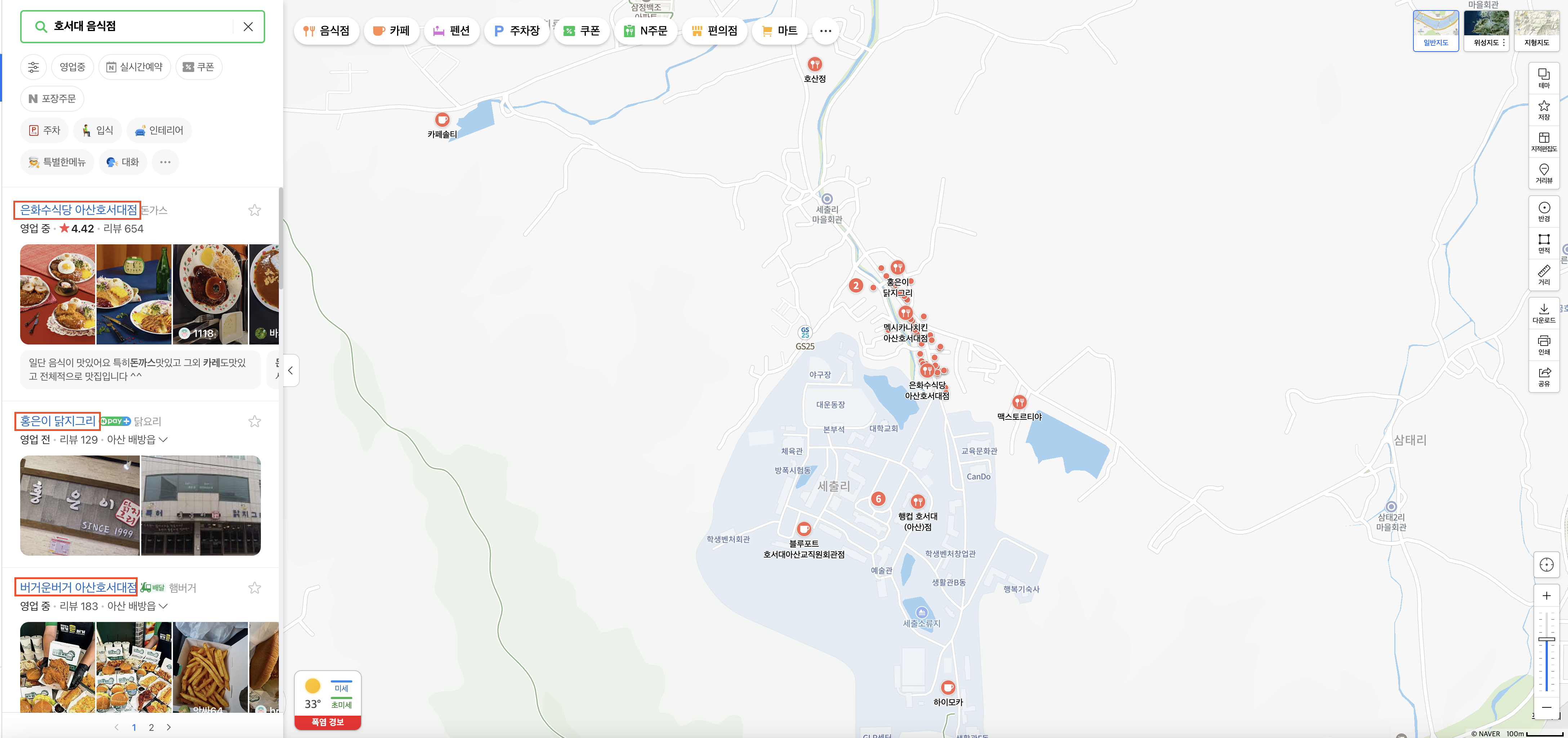
오늘 목표는 상단에 표시한 것처럼 "호서대 음식점"에 해당하는 가게들의 이름을 크롤링하는 것입니다. 이를 원활하게 진행하려면 현재 컴퓨터가 보고 있는 HTML 창을 변경해야 합니다. 즉, 지도가 아닌 하단에 표시된 "호서대 음식점" 리스트를 대상으로 작업을 수행할 수 있도록 설정을 변경해야 합니다. 이를 위해, 컴퓨터가 바라보는 iframe을 적절히 변경해주어야 합니다.

3) ifrmae 변경
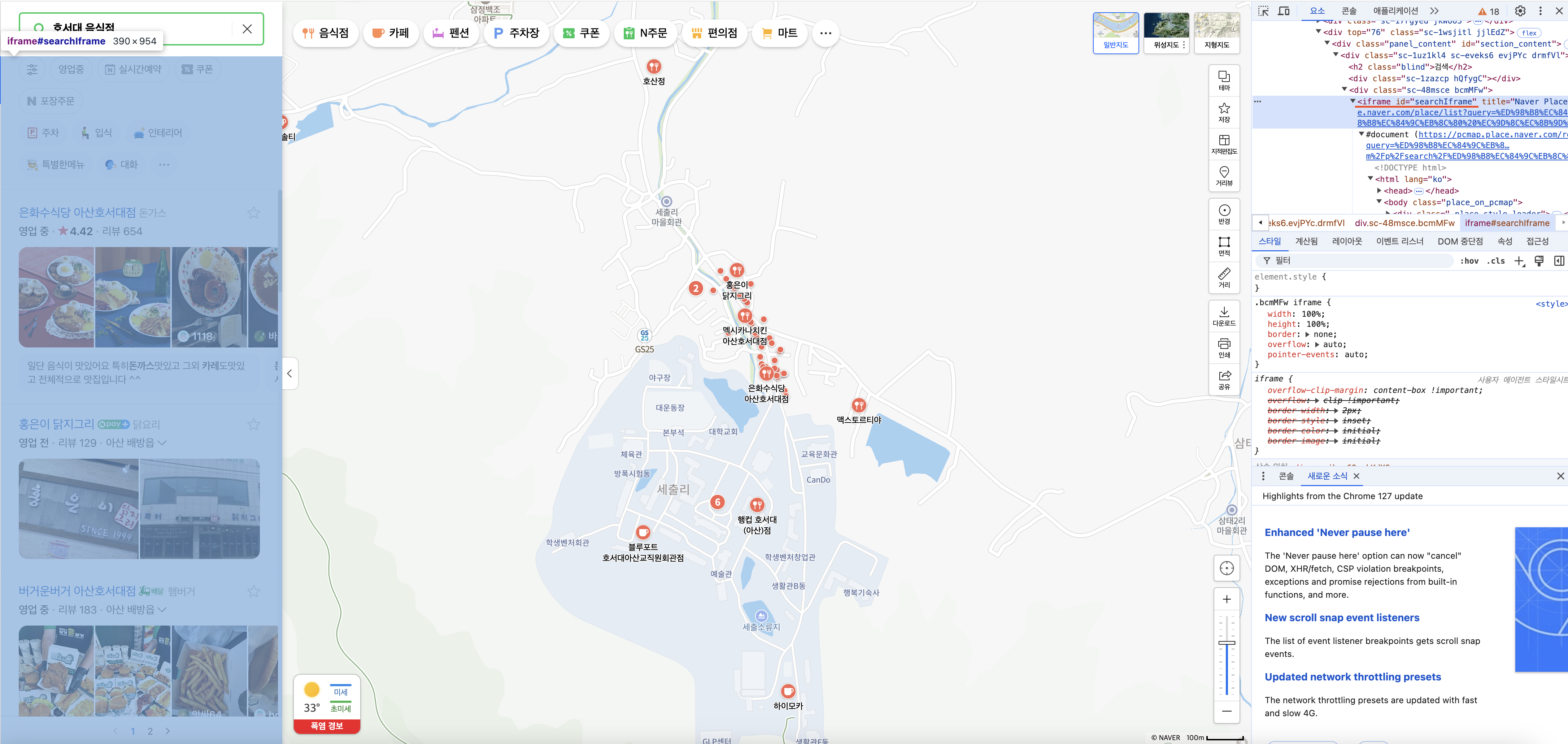
개발자 도구를 통해 검색결과에 해당하든 iframe의 id 값을 확인할 수 있습니다. 이제 이 id 를 이용해서 컴퓨터가 바라보는 iframe을 변경해주면 됩니다.
driver.switch_to.frame("searchIframe")
코드는 간단합니다
# 페이지 다운
def page_down(num):
body = driver.find_element(By.CSS_SELECTOR, "body")
body.click()
for i in range(num):
body.send_keys(Keys.PAGE_DOWN)
# 페이지 리스트
next_btn = driver.find_elements(By.CSS_SELECTOR, ".zRM9F> a")
page_down(40)page_down() 함수는 검색 결과가 페이징 알고리즘으로 구현되어 있어, 스크롤을 내려 모든 가게가 화면에 보일 수 있도록 하기 위해 제가 직접 구현한 것입니다. next_btn은 페이지 스크롤을 모두 내려 검색결과가 다 나왔을때 다음 페이지로 넘어가기 위한 페이지 리스트입니다.
4) 본격적인 Crawling
# 크롤링 (페이지 리스트 만큼)
for btn in range(len(next_btn))[1:]: # next_btn[0] = 이전 페이지 버튼 무시 -> [1]부터 시작
store_list = driver.find_elements(By.CSS_SELECTOR, ".UEzoS.rTjJo")
names = driver.find_elements(By.CSS_SELECTOR, ".place_bluelink.TYaxT") # (3) 가게명
for data in range(len(store_list)): # 가게 리스트 만큼
sleep(1)
# 가게 이름 가져오기
store_name = names[data].text
# 로딩 기다리기
sleep(1)
store_dict["가게 이름"].append(store_name)
sleep(1)
# 다음 페이지 버튼 누를 수 없으면 종료
if not next_btn[-1].is_enabled():
break
if names[-1]: # 마지막 주차장일 경우 다음버튼 클릭
next_btn[-1].click()
sleep(2)
else:
print("페이지 인식 못함")
break
driver.quit()
가게들의 리스트와 가게명에 해당하는 클래스를 개발자 도구를 통해 찾은 후, BY.CSS_SELECTOR를 사용해 지정해줍니다. 이때 주의할 점은, 개발자 도구에서 클래스명이 .place_bluelink TYaxT와 같이 띄어쓰기로 구분되어 있어도, 이를 BY.CSS_SELECTOR에서 사용할 때는 .을 사용해 .place_bluelink.TYaxT처럼 연결해야 한다는 것입니다. 그리고 작업이 끝나면 driver.quit() 를 사용해 창을 꼭 닫아주도록 합니다.
5) Crawling 데이터 저장
이제 크롤링한 데이터를 저장하겠습니다. 원하는 파일 형식에 맞게 저장할 수 있으며, 저는 이 데이터를 xlsx 형식으로 저장였습니다.
import pandas as pd
df = pd.DataFrame(store_dict)
# 엑셀 파일로 저장
df.to_excel("food_data.xlsx", index=False)
pandas 라비르러리를 이용해 DataFrame 형태로 데이터를 저장하고 이를 excel로 변환시켜주었습니다. 이러한 크롤링 과정을 통해 아래의 결과를 얻을 수 있었습니다.

6) Crawling 데이터 필터링
위의 과정을 통해 데이터를 성공적으로 저장할 수 있었지만, 네이버 지도에서 모든 리스트를 가져오다 보니 현재 존재하지 않는 가게나 학교 근처가 아닌 다소 떨어진 가게들의 정보도 함께 수집되었습니다. 저는 현재 존재하는 학교 인근의 가게 정보만을 원했기 때문에, 이를 위해 필터링 과정을 추가로 거쳤습니다.
(1) 학교 인근 가게 set 생성
food_set = {'은화수식당', '홍은이', '버거운버거', '곱창1번지', '메가MGC커피','...'}
여기서는 시간 복잡도를 고려하여 list가 아닌 set을 사용하였습니다. ( list : O(n), set : O(1) )
(2) Crawling에 logic 추가
from food_list import food_set
if any(food in store_name for food in food_set):
store_dict["가게 이름"].append(store_name)any 함수를 사용한 이유는 가게 이름이 전부 일치하지 않더라도 일부 핵심 키워드가 일치하면 해당 가게를 집합에 포함시키기 위해서입니다. 이를 통해 보다 유연하게 가게 정보를 필터링할 수 있도록 구성하였습니다. 이를 통해 성공적으로 학교 인근 가게명을 크롤링해올 수 있었습니다.
참고자료
'CampusMeet' 카테고리의 다른 글
| [AutoScaling] 다양한 AutoScaling 전략 (0) | 2024.09.19 |
|---|---|
| [DNS] Nginx ingress controller 와 Domain (0) | 2024.09.15 |
| [NKS] NKS를 활용한 배포 (1) (0) | 2024.09.08 |
| [CS] .env 파일 유출 문제와 해결 방안 (3) | 2024.08.28 |
| [Backend] FastAPI (0) | 2024.08.14 |