728x90
반응형
1. Text Embedding 이란
2. 임베딩 방법
3. Word2vec
1. Text Embedding 이란
- 기존의 비정형 데이터 형태의 자연어 데이터를 n차원의 수치형 벡터로 표상화 시킨 데이터
- 단순히 텍스트를 숫자로 변환하는 것이 아니라 해당 언어가 가지는 의미적 컨텍스트를 지닌 숫자로 변환
- 머신러닝 알고리즘 활용 시 분석에 용이한 형태
2. 임베딩 방법
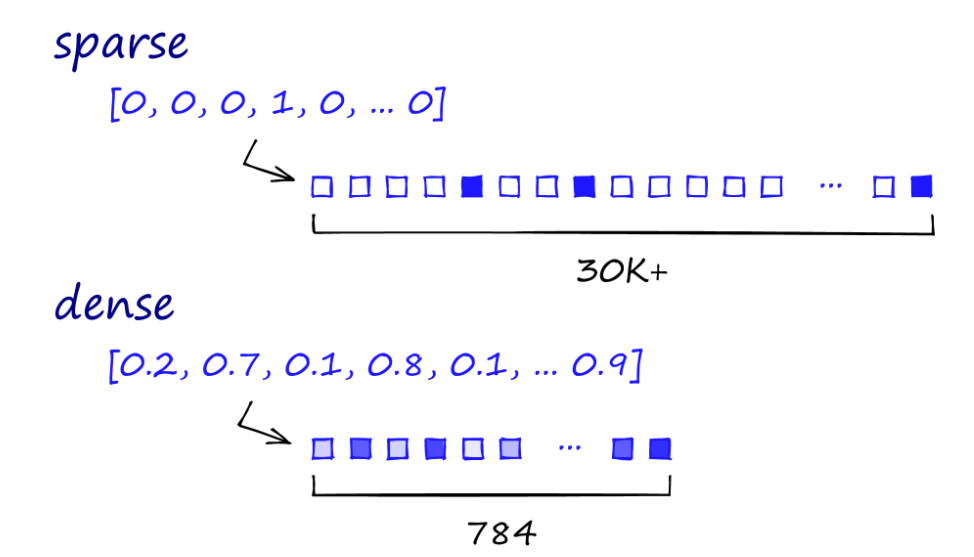
1) Sparse Vector(구문 정보 중심)
- 문장 내에 단어의 등장 여부, 등장 빈도 등 구문론적 정보가 표현
(의미가 다르더라도 동일한 단어 구성이라면 벡터의 생김새가 동일 ) - 대부분의 요소가 0으로 채워지고, 소수의 요소만이 0이 아닌 값을 갖는 벡터
- 일반적으로 희소 벡터는 실제 데이터에 비해 매우 큰 차원을 가지는 경우에 사용
- 비효율적인 저장공간
- 단어의 의미를 나타내지 못하기 때문에 벡터간의 연산이 불가능하다는 단점 존재
2) Dense Vector (의미 정보 중심)
- 희소 벡터와는 반대로 대부분의 요소가 0이 아닌 값을 갖는 벡터
- 벡터의 각 요소는 해당 단어의 의미나 특성을 잘 나타냄 (여러 차원들의 값의 집합이 하나의 의미적 요소를 지님)
- 각 차원은 단어의 의미적 특징을 나타내며, 비슷한 의미를 가진 단어들은 해당 차원에서 비슷한 위치에 매핑
- 밀집 벡터의 차원은 사용자가 설정할 수 있지만, 일반적으로 사용자가 직접 설정하는 것보다는 사전 훈련된 임베딩 모델을 사용하는 것이 일반적
- 효율적인 저장공간
- 통상적으로 사용하는 벡터 임베딩 방법
3. Word2vec
1) 정의
- 초기에 대중적으로 알려진 Dense Embedding Model
- 단어의 의미를 여러 차원에 분산하여 표현하는 구조 (문장 x)
- 사칙연산으로 관계성 모델링 가능
(해당 벡터들이 의미적인 정보가 잘 담겨있는 형태로 학습이 됐다는 것을 의미) - 하나의 hidden layer로 이루어진 Shallow Neural Network 모델
- CBOW, Skip-Gram 의 학습방식으로 모델 학습 (Skip-Gram > CBOW)
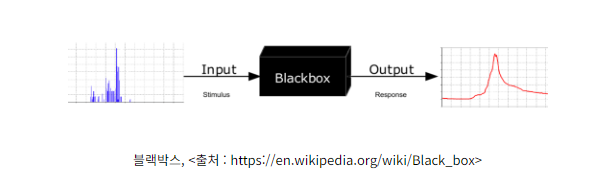
*Blackbox*
Dense Embedding은 여러 차원의 값으로 이루어진 데이터를 하나의 의미있는 표현으로 변환합니다. 그러나 각 차원이 무엇을 의미하는지를 명확히 이해하기는 어렵습니다. 이렇게 모델이 입력을 처리하는 내부 과정이나 각 차원의 의미를 파악하기 어려운 것을 "Blackbox"라고 합니다.
2) 학습 방법
| CBOW | Skip-Gram |
| 주변 단어로 중심 단어를 예측 | 중심 단어로 주변 단어를 예측 |
3) Word2Vec의 한계점
- 같은 표현이여도 주변 문맥에 따라 의미가 달라 지지만 이에 대한 고려가 없음
ex) 하늘이 시퍼렇다 / 얼굴이 시퍼렇다 - 단어 단위의 임베딩이다 보니, 같은 단어인데 다른 의미를 가지는 다의성 보유 단어들에 대한 고려 없이 단어 하나당 한개의 벡터로만 표현됨
ex) 배(pear) / 배(ship) - 어떤 학습 컨텍스트를 가진 문서인지에 따라 그 의미가 표현되는 방식이 바뀌기때문에 사용자의 의도가 제대로 반영이 되기가 어려움
ex) 학습 컨텍스트에서 배(pear) 가 많이 사용 되었는데 사용자의 의도는 배(ship) 일 경우 잘못된 유사도가 측정됨
참고자료
https://www.pinecone.io/learn/series/nlp/dense-vector-embeddings-nlp/
https://broccoli45.tistory.com/31
패스트 캠퍼스 - 벡터DB로 구현하는 LLM 기반 검색 엔진 & 유사 상품 추천 시스템 (ft. Pinecone & Langchain)
'CS' 카테고리의 다른 글
| [네트워크] 외부에서 사내 서버 접근 (0) | 2025.07.05 |
|---|---|
| [CS] 사설 GitLab 서버에서 SSH로 프로젝트 클론하기 (0) | 2024.11.29 |
| [CS] vscode kernel 가상환경 안보임 (0) | 2024.07.02 |
| [CS] gensim ImportError (0) | 2024.05.03 |
| [CS] CRLF vs LF (2) | 2024.02.20 |